Privacy-First Synthetic Data
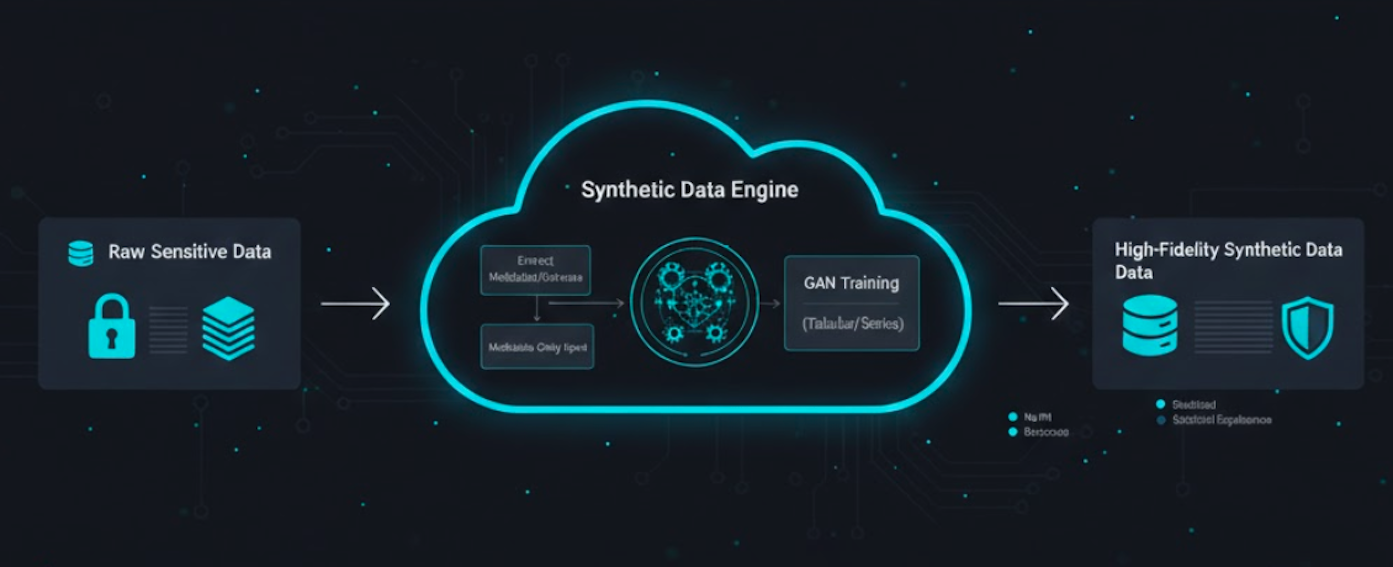
Synthetic data generation solves the fundamental bottleneck of data access. By training advanced generative models on sensitive information, we create an entirely artificial dataset that replicates the patterns, correlations, and temporal dependencies of the real world without containing any actual PII.
Our approach specializes in complex Tabular and Time-Series data, enabling rapid development and testing cycles even in highly regulated environments where raw data access is restricted.
Advanced Generative Capabilities
GAN-Driven Tabular Data
Using Conditional GANs to capture complex relationships between categorical and numerical features, ensuring joint distributions remain consistent.
Time-Series Fidelity
Specialized architectures designed to preserve temporal dynamics, seasonality, and autocorrelation for financial logs and IoT sensor data.
Metadata-Led Generation
Facilitate data creation even when source data is unavailable. Our engine scaffolds realistic data structures from high-level schema descriptions.
Differential Privacy Integration
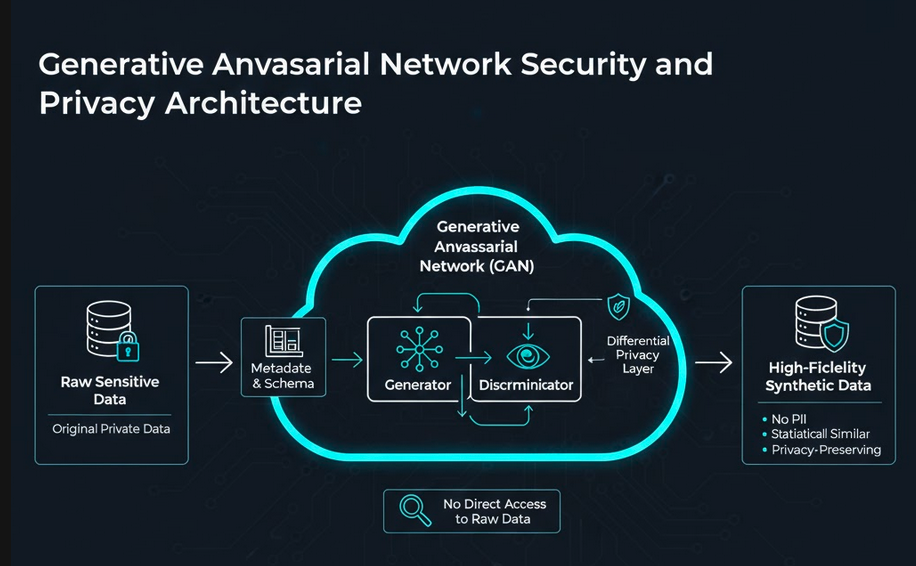
Mathematically guarantee privacy by injecting noise during training, ensuring individual records cannot be re-identified via linkage attacks.
Automated Schema Discovery
Smart parsing of existing database schemas to automatically identify constraints, primary keys, and statistical bounds for accurate modeling.
Utility Benchmarking
Comprehensive metrics to compare synthetic data utility against original sets, measuring correlation coefficients and ML model performance.
The Generation Framework
The Discriminator-Generator Loop
Our framework employs a competitive learning process where a Generator creates data while a Discriminator validates its authenticity until the synthetic output is statistically indistinguishable from the real source.
Zero-Data Scaffolding
In scenarios where data is too sensitive to move, we utilize Metadata descriptions to define the "DNA" of the required dataset, allowing valid test data generation without seeing a single real record.
High-Value Use Cases
Safe Sandbox Environments
Provide developers with 100% safe synthetic versions of production databases for testing and integration without any risk of breach.
AI/ML Model Training
Augment rare event data or balance biased datasets to improve the accuracy and fairness of predictive models in finance and healthcare.
Compliance-Free Sharing
Share high-fidelity datasets across borders or with research institutions without the legal overhead of GDPR, CCPA, or HIPAA data transfer agreements.