Professional Data Anonymisation
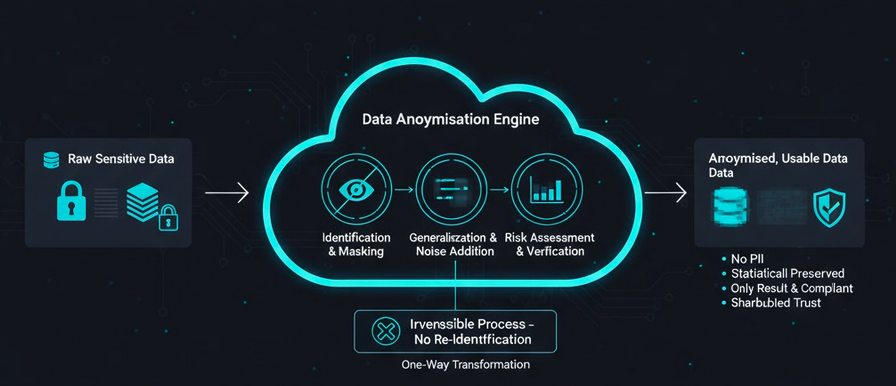
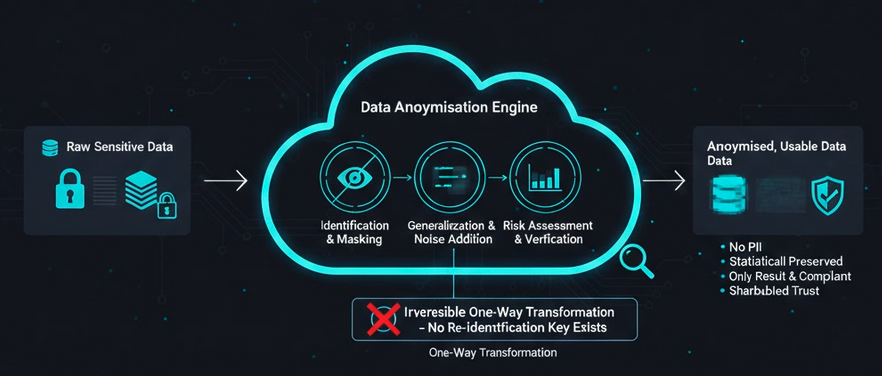
Data Anonymisation is the process of irreversibly altering datasets so that individuals cannot be identified. By removing or masking Personally Identifiable Information (PII), organizations can safely utilize data for research, analytics, and sharing without breaching GDPR or other privacy mandates.
Our framework employs multi-layered transformation strategies—including generalization and perturbation—to safeguard against re-identification attacks while maintaining the statistical correlations necessary for accurate business intelligence.
Transformation Techniques
K-Anonymity
Ensuring that any individual in the dataset cannot be distinguished from at least k-1 other individuals, effectively hiding them in a crowd of similar records.
Pseudonymisation
Replacing private identifiers with cryptographically secure tokens (pseudonyms), allowing for data linkage while keeping real-world identities hidden.
Data Masking & Redaction
Applying dynamic or static masking to hide specific fields—such as credit card numbers or government IDs—at the point of access or storage.
Noise Addition
Implementing statistical perturbation by adding small amounts of random noise to numerical fields to prevent exact value matching without altering averages.
Generalization
Reducing granularity—such as converting specific birth dates to age ranges or precise locations to city-level regions—to lower re-identification risk.
L-Diversity & T-Closeness
Advanced statistical models that ensure sensitive attributes within a group are sufficiently diverse, protecting against attribute disclosure attacks.
Security & Privacy Architecture
Irreversible De-identification
Our architecture focuses on the destruction of the link between the data and the individual. By utilizing "One-Way" hashing and attribute suppression, we ensure that once data is anonymised, it can never be reverted to its original state.
Risk Assessment & Monitoring
The framework includes automated re-identification risk scoring, simulating known attack vectors to ensure your anonymised datasets remain secure against modern linkage threats.
High-Value Use Cases
Public Data Portals
Safely release government or municipal datasets to the public for transparency and innovation while guaranteeing citizen privacy.
Cloud Analytics Migration
Anonymise sensitive on-premise data before moving it to third-party cloud environments for processing, reducing your organization's risk profile.
Cross-Departmental Sharing
Enable internal teams to collaborate on user behavior trends without granting unnecessary access to the raw identities of your customers.